We’ve recently been experimenting with the use of ObservableHQ notebooks for gathering and transforming data in the context of digital research. This post walks through a few recent examples of notebooks from recent Public Data Lab projects.
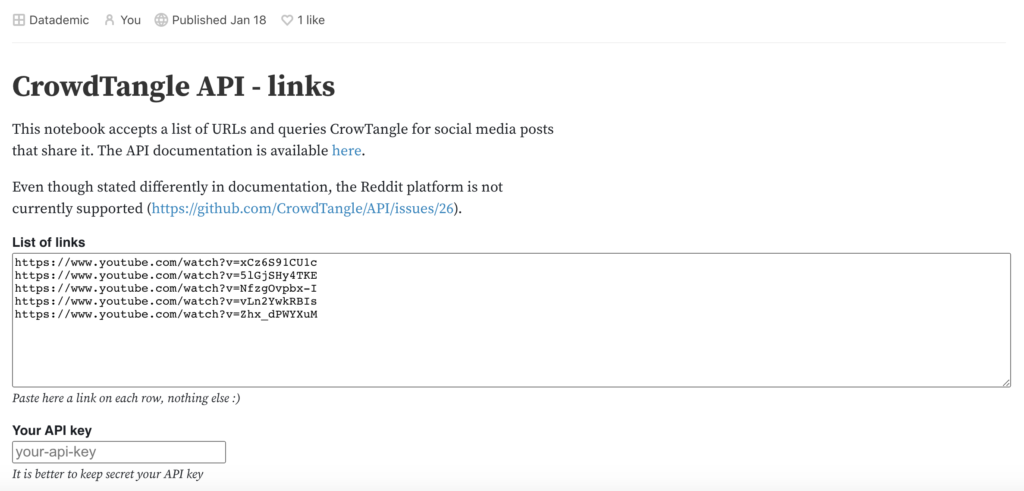
In one project we wanted to use the CrowdTangle “Links” API to fetch data about how certain web pages were shared online and across different platforms. After gaining access to relevant end points, we could adopt different means to call the APIs and retrieve data: such as using something like Postman (a general-purpose interface to call endpoints), or writing custom scripts (for example in Python or Javascript).
Code notebooks are a third option that lies somewhere in between these options. Designed for programmers, notebooks allow for iterative manipulation and experimentation with code whilst keeping track of creative processes by commenting on the thinking behind each step.
Notebooks allow us to both write and run custom scripts as well as creating simple interfaces for those who may not code. Thus we can use them to help researchers, students and external collaborators to collect data, making it easier to call APIs, setting parameters, or perform manipulations.
ObservableHQ is one solution for writing programming notebooks, it runs in the browser and is oriented towards data and visualisations (“We believe thinking with data is an essential skill for the future”). Hence, we thought it could be a good starting point for what we wanted to do.