The first of a two-part series providing critical considerations for reporting on environmental issues with social media data
By Thais Lobo, Rina Tsubaki, Liliana Bounegru, Jonathan Gray and Gabriele Colombo
Social media platforms and online services can reveal how forests, rivers, mountains, animals — and human encounters with them — are seen, valued, and contested in near real-time. This isn’t without its challenges. Online platforms shape what we see and whose voices are amplified. While they can’t be treated as neutral reflections of how we relate to the environment, when taken as indications rather than comprehensive or unbiased sources, they can be useful leads for climate reporting.
This piece is the first of a two-part series with critical considerations for climate data journalists interested in how online activity about environmental issues can reveal new story angles and generate evidence to support on-the-ground reporting. This first piece focuses on practical tips for searching and analysing digital data, while the second explores how to add depth and context to those online findings.
The checklist series draws on findings from our research on online engagement with forest restoration, carried out as part of the EU-funded SUPERB project. As part of the project, we looked at online activity across five digital platforms linked to twelve European forest sites where SUPERB is working on ecological restoration. The insights gathered here aim to support climate reporting with and about digital platforms, considering both the opportunities and limitations these sources offer to journalists.
We are pleased to announce the 3rd edition of the Summer School in Digital Methods for Critical Consumer Studies, which will take place in Como – from September 22 to 26, 2025.
This year’s theme is: Artificial intelligence as a methodological resource and its applications for consumer culture research.
The School will focus on the intersection between Digital Methods, consumer culture, and AI technologies such as large language models (LLMs), exploring both technical and critical perspectives. The School is meant for master and PhD students who wish to learn digital methods and apply them to their research project in the field of consumer culture. The programme includes lectures, workshops, keynote talks, and group work, delivered by an international and interdisciplinary faculty. Confirmed keynote speakers are: Joonas Rokka (Emlyon Business School), Giorgia Aiello (University of Milan) and Gabriele Colombo (Politecnico di Milano). The Summer School is organized by the University of Milan, in collaboration with: SOMET – PhD Programme in Sociology and Methodology of Social Research, Milan School of Media and Communication, PhD in Communication Science and Practice, University of Pavia.
Applications are open until June 6, 2025
To participate in the Summer School, candidates must send their applications at this email address: laura.bruschi@unimi.it, by 6 June 2025. Applications must entail a CV and presentation letter, containing: a) brief bio; b) interests of research; c) motivation to participate in the Summer School.
We welcome applications from MA and PhD students, early-career researchers, and professionals interested in digital methods, AI, media, and consumer studies.
Please feel free to share this call with colleagues or students who might be interested.
Best regards,
On behalf of the School Directors: A. Caliandro, A. Gandini, M. Airoldi
How can soundscaping prompt reconsideration of the lives, cultures and futures of forests?
To explore this we’re organising a forestscapes listening lab at Science Gallery London, as part of Pulse of the Planet on 21st March 2025 from 6.30pm. You can find out more and register here.
The listening lab is part of the forestscapes project, which examines how soundscaping can surface different ways of knowing, imagining and experiencing forests.
As part of this project we are developing generative arts-based methods for recomposing collections of sound materials to support “collective inquiry” into forests as living cultural landscapes.
At the listening lab we will be using supercollider for live algorithmic recomposition of collections of forest related sounds – including field recordings from forest research and restoration projects, as well as sounds associated with forest sites and forest issues on online platforms such as YouTube and TikTok.
In contrast to listening as individual immersion in curated recreations of nature – the lab will explore listening as a collective practice of unsettling and reconsidering nature-culture relations and how ecologies are mediatised, commodified, laundered and contested.
If you’d like to get updates on the forestscapes project you can sign up here. If you’re interested in collaborating or hosting a forestscapes workshop you can find contact details here.
In January 2025 a group of us met at the Digital Methods Winter School at the University of Amsterdam to explore how TikTok was used during and after the elections.
We explored ways of playing back election TikTok video collections to understand what happened.
We experimented with formats for retrospective display – drawing inspiration from creative coding, algorithmic composition, multiperspective live action replays, and the aesthetics of forensic reconstruction.
Following research on visual methods for studying folders of images (Niederer and Colombo, 2024; Colombo, Bounegru & Gray, 2023) and analytical metapicturing (Rogers, 2021), these formats display multiple videos simultaneously to surface patterns and resonances across them.
Beyond evaluating informational content, group replay formats can also highlight the everyday situations, aesthetics and affective dimensions of election TikTok videos – from sexualised lip-syncing to rousing AI anthems, sponsored micro-influencer testimonials to post-communist nationalist nostalgia.
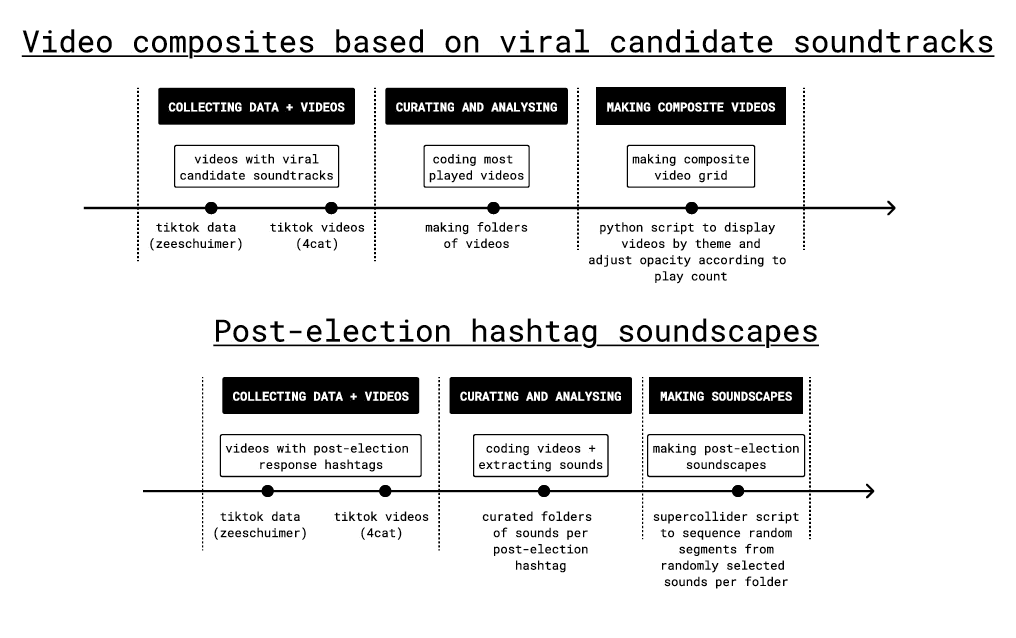
We explored two approaches for critically replaying Romanian election videos: making video composites based on viral candidate soundtracks, and making post-election hashtag soundscapes. For the former we used a Python script to display videos by theme and adjust opacity according to play count. For the latter we used soundscaping scripts developed as part of the Forestscapes project.
For the video composites we used as case studies two viral soundtracks associated with ultranationalist Călin Georgescu and the centre-right, pro-EU, Save Romania Union candidate Elena Lasconi.
Our preliminary findings indicate that successful pro-Georgescu propaganda using the “SustinCalin Georgescu” soundtrack relies on memetic imitation of the message and affective resonances of the song. TikTok influencers and everyday users translate these into popular formats such as lipsyncs and ASMR videos effectively blending textual, visual, and audio elements.
Gender, sexuality and race are prominent themes in the most engaged with propagandist videos for both campaigns. In pro-Georgescu content, popular endorsement videos often feature white women in either sexualised roles or domestic family settings. Homophobic and transphobic videos with male characters in dresses parody the opponent’s and her party’s association with LGBTQ issues, fuelling the audience’s strong emotions towards minoritised groups.
For the “Hai Lasconi la Putere” propagandistic song, the most significant finding is its successful appropriation for counter-propaganda to spread racist, sexist, homophobic, and transphobic content targeting minoritised groups. These videos do not only target Lasconi but more worryingly these groups themselves, amplifying fears and prejudices, as often reflected in the comments.
The second technique we explored was post-election hashtag soundscaping. We examined hashtags such as: #anularealegeri, #aparamdemocratia, #calingeorgescupresedinte, #cg, #cinetaceestecomplice #demisiaccr, #demisiaiohanis, #lovituradestat, #romaniatacuta, #romaniavanduta, #stegarul, #stegaruldac and #votfurat.
For example, in the #stegaruldac soundscape the simultaneous replay of TikTok video soundtracks associated with this hashtag enables a synthetic mode of attending not only to the content of propaganda but also to the various settings in which propaganda unfolds in everyday life (e.g. in the home and on the street) as well as associated affective atmospheres.
You can explore our project poster and some of our video composites and soundscapes here.
The Media of Cooperation Research Centre at the University of Siegen is hiring a Digital Methods Research Associate. Further details can be found here and copied below.
[- – – – – – – ✄ – – – snip – – – – – – – – – -]
Job title: Research Associate – Digital Methods / Scientific Programmer (SFB 1187)
Area: Faculty I – Faculty of Philosophy | Scope of position: full-time | Duration of employment: limited | Advertisement ID: 6274
We are an interdisciplinary and cosmopolitan university with currently around 15,000 students and a range of subjects from the humanities, social sciences and economics to natural sciences, engineering and life sciences. With over 2,000 employees, we are one of the largest employers in the region and offer a unique environment for teaching, research and further education.
In Faculty I – Faculty of Philosophy, SFB 1187 Media of Cooperation, we are looking for a research assistant in the field of Digital Methods/Scientific Programming as soon as possible under the following conditions:
100% = 39.83 hours
Salary group 13 TV-L
limited until December 31, 2027
YOUR TASKS
Support in the development and teaching of digital research methods within the framework of the SFB Media of Cooperation and teaching in the media studies courses.
Development, implementation and updating of software tools for working with digital research methods, as well as further development of existing open source research software, such as 4CAT.
Support in the collection, analysis and visualization of data from online media within the framework of the research projects of the SFB Media of Cooperation, especially in the area of social media platforms, audiovisual platforms, generative AI, apps and sensory media.
Administration and maintenance of the digital research infrastructure for data collection, archiving and analysis
Participation in the planning and implementation of media science research projects
Technical support for workshops and events
Networking with developers of research software, also internationally
Teaching obligation: 4 semester hours per week
YOUR PROFILE
Completed academic university degree (diploma, master’s, magister, teaching qualification, comparable foreign degree) in computer science, business informatics, media studies or a related discipline
Experience with system administration and support of server environments (Linux) as well as the operation of web-based applications (e.g. 4CAT)
Very good knowledge of developing applications with Python and database systems (MySQL or similar) or willingness to deepen this
Basic knowledge of web development with JavaScript, PHP, HTML, CSS, XML or willingness to acquire this
Affinity for working with data from platforms, apps, web or other data-intensive media, for example using scraping or API Retrieval
Ability to work in a team, creativity and very good communication skills
Fluent written and spoken English
Experience in the conception and development of research software and interest in supporting the research of the SFB Media of Cooperation
OUR OFFER
Promotion of your own scientific or artistic qualification in accordance with the Scientific Temporary Employment Act
Various opportunities to take on responsibility and make a visible contribution in the field of research and teaching
A modern understanding of leadership and collaboration
Good compatibility of work and private life, for example through flexible working hours and place of work as well as support with childcare
Comprehensive personnel development program
Health management with a wide range of prevention and advice services
We look forward to receiving your application by December 24, 2024.
Please only apply via our job portal (https://jobs.uni-siegen.de.) Unfortunately, we cannot consider applications in paper form or by email.
German language skills are nice to have, but not required.
How are digital objects such as hashtags, links, likes and images involved in the production of forest politics? This chapter explores this through collaborative research on the dynamics of online engagement with the 2019 Amazon forest fires. Through a series of empirical vignettes with visual materials and data from social media, we examine how digital platforms, objects and devices perform and organise relations between forests and a wide variety of societal actors, issues, cultures – from bots to boycotts, agriculture to eco-activism, scientists to pop stars, indigenous communities to geopolitical interventions. Looking beyond concerns with the representational (in-)fidelities of forest media, we consider the role of collaborative methodological experiments with co-hashtag networks, cross-platform analysis, composite images and image-text variations in tracing, eliciting and unfolding the digital mediation of ecological politics. Thinking along with research on the social lives of methods, we consider the role of digital data, methods and infrastructures in the composition and recomposition of problems, relations and ontologies of forests in society.
Here’s the book blurb:
Digital ecologies draws together leading social science and humanities scholars to examine how digital media are reshaping the futures of conservation, environmentalism, and ecological politics. The book offers an overview of the emerging field of interdisciplinary digital ecologies research by mapping key debates and issues in the field, with original empirical chapters exploring how livestreams, sensors, mobile technologies, social media platforms, and software are reconfiguring life in profound ways. The collection traverses contexts ranging from animal exercise apps, to surveillance systems on the high seas, and is organised around the themes of encounters, governance, and assemblages. Digital ecologies also includes an agenda-setting intervention by the book’s editors, and three closing chapter-length provocations by leading scholars in digital geographies, the environmental humanities, and media theory that set out trajectories for future research.
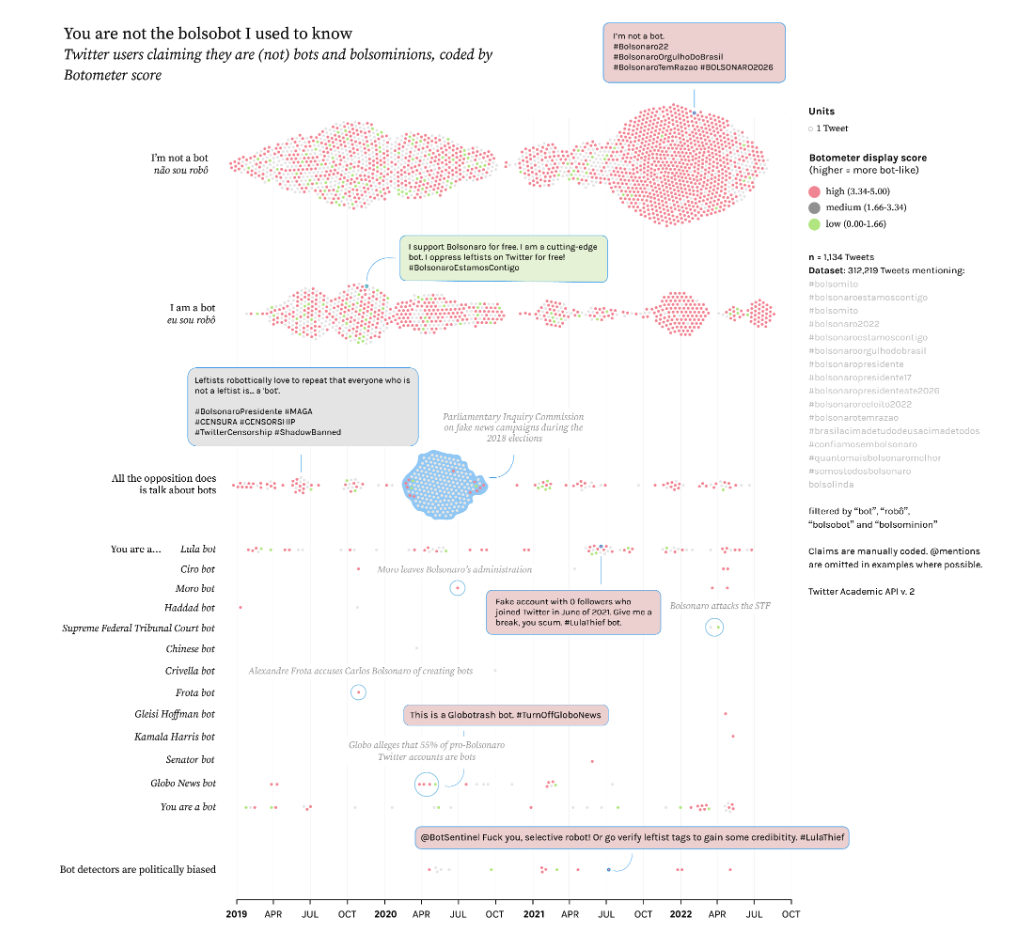
An article on “Quali-quanti visual methods and political bots: A cross-platform study of pro- & anti- bolsobots” has just been published in the special issue “Methods in Visual Politics and Protest” of the Journal of Digital Social Research, co-authored by Public Data Lab associates Janna Joceli Omena, Thais Lobo, Giulia Tucci, Elias Bitencourt, Emillie de Keulenaar, Francisco W. Kerche, Jason Chao, Marius Liedtke, Mengying Li, Maria Luiza Paschoal, and Ilya Lavrov.
The article provides methodological contributions for interpreting bot-associated image collections and textual content across Instagram, TikTok and Twitter/X, building on a series of data sprints conducted as part of the Public Data Lab “Profiling Bolsobot Networks” project.
The full text is available open access here. Further details and links can be found at the project page. Below is the abstract:
Computational social science research on automated social media accounts, colloquially dubbed “bots”, has tended to rely on binary verification methods to detect bot operations on social media. Typically focused on textual data from Twitter (now rebranded as “X”), these methods are prone to finding false positives and failing to understand the subtler ways in which bots operate over time and in particular contexts. This research paper brings methodological contributions to such studies, focusing on what it calls “bolsobots” in Brazilian social media. Named after former Brazilian President Jair Bolsonaro, the bolsobots refer to the extensive and skilful usage of partial or fully automated accounts by marketing teams, hackers, activists or campaign supporters. These accounts leverage organic online political culture to sway public opinion for or against policies, opposition figures, or Bolsonaro himself. Drawing on empirical case studies, this paper implements quali-quanti visual methods to operationalise specific techniques for interpreting bot-associated image collections and textual content across Instagram, TikTok and Twitter/X. To unveil the modus operandi of bolsobots, we map the networks of users they follow (“following networks”), explore the visual-textual content they post, and observe the strategies they deploy to adapt to platform content moderation. Such analyses tackle methodological challenges inherent in bot studies by employing three key strategies: 1) designing context-sensitive queries and curating datasets with platforms’ interfaces and search engines to mitigate the limitations of bot scoring detectors, 2) engaging qualitatively with data visualisations to understand the vernaculars of bots, and 3) adopting a non-binary analysis framework that contextualises bots within their socio-technical environments. By acknowledging the intricate interplay between bots, user and platform cultures, this paper contributes to method innovation on bot studies and emerging quali-quanti visual methods literature.
The article explores testing situations – moments in which it is no longer possible to go on in the usual way – across scales during the COVID-19 pandemic through interpretive querying and sub-setting of Twitter data (“data teasing”), together with situational image analysis.
The full text is available open access here. Further details and links can be found at this project page. The abstract and reference are copied below.
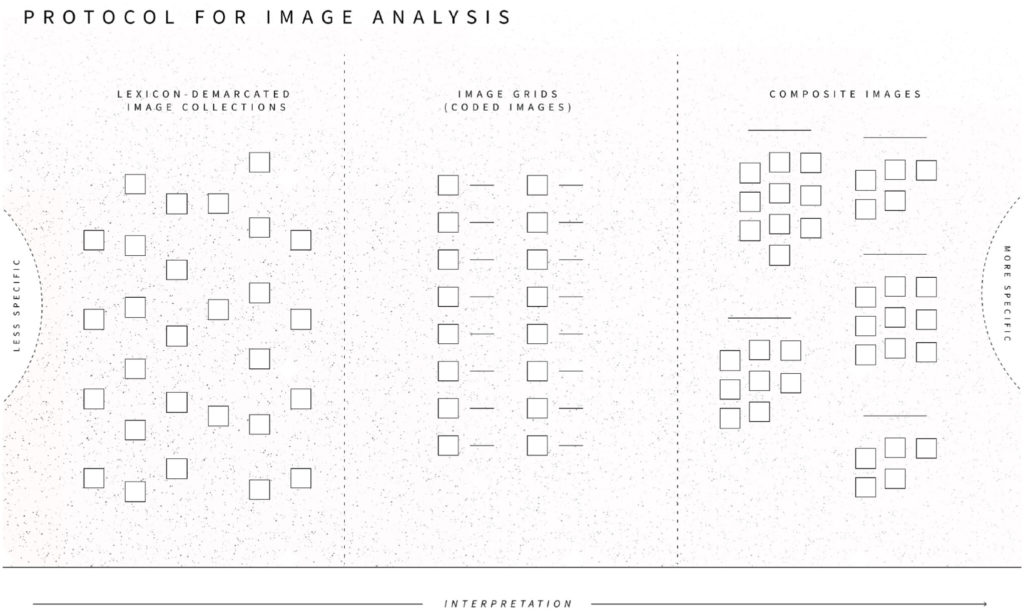
How was testing—and not testing—for coronavirus articulated as a testing situation on social media in the Spring of 2020? Our study examines everyday situations of Covid-19 testing by analyzing a large corpus of Twitter data collected during the first 2 months of the pandemic. Adopting a sociological definition of testing situations, as moments in which it is no longer possible to go on in the usual way, we show how social media analysis can be used to surface a range of such situations across scales, from the individual to the societal. Practicing a form of large-scale data exploration we call “interpretative querying” within the framework of situational analysis, we delineated two types of coronavirus testing situations: those involving locations of testing and those involving relations. Using lexicon analysis and composite image analysis, we then determined what composes the two types of testing situations on Twitter during the relevant period. Our analysis shows that contrary to the focus on individual responsibility in UK government discourse on Covid-19 testing, English-language Twitter reporting on coronavirus testing at the time thematized collective relations. By a variety of means, including in-memoriam portraits and infographics, this discourse rendered explicit challenges to societal relations and arrangements arising from situations of testing and not testing for Covid-19 and highlighted the multifaceted ways in which situations of corona testing amplified asymmetrical distributions of harms and benefits between different social groupings, and between citizens and state, during the first months of the pandemic.
Marres, N., Colombo, G., Bounegru, L., Gray, J. W. Y., Gerlitz, C., & Tripp, J. (2023). Testing and Not Testing for Coronavirus on Twitter: Surfacing Testing Situations Across Scales With Interpretative Methods. Social Media + Society, 9(3). https://doi.org/10.1177/20563051231196538
Following the recent release of Gephi Lite, an open-source web-based visual network exploration tool, we interviewed its developers about the background of the project, what they’ve done and future plans…
What is Gephi Lite?
Gephi Lite can actually be defined in two ways. The first definition follows the name we chose: Gephi Lite is a lighter version of the Gephi desktop software, targeting users who need to work on smaller networks with less complex operations in mind.
The second definition is more focused on the technical context: Gephi Lite is a serverless web application to drive visual network analysis. There are no more requirements than an internet connection and a modern web browser.