A call for papers and experiments for Generative Methods: AI as collaborator and companion in the social sciences and humanities taking place in Copenhagen, 6-8th December 2023. Further details can be found here and copied below.

A call for papers and experiments for Generative Methods: AI as collaborator and companion in the social sciences and humanities taking place in Copenhagen, 6-8th December 2023. Further details can be found here and copied below.

A new working paper on “Testing ‘AI’: Do We Have a Situation?” based on conversation between Noortje Marres and Philippe Sormani has just been published as part of a working paper series from “Media of Cooperation” at the University of Siegen. The paper can be found here and further details are copied below.
The new publication »Testing ‘AI’: Do We Have a Situation?« of the Working Paper Series (No. 28, June 2023) is based on the transcription of a recent conversation between the authors Noortje Marres und Philippe Sormani regarding current instances of the real-world testing of “AI” and the “situations” they have given rise to or as the case may be not. The conversation took place online on the 25th of May 2022 as part of the Lecture Series “Testing Infrastructures” organized by the Collaborative Research Center (CRC) 1187 “Media of Cooperation” at the University of Siegen Germany. This working paper is an elaborated version of this conversation.
In their conversation Marres and Sormani discuss the social implications of AI based on three questions: First they return to a classic critique that sociologists and anthropologists have levelled at AI namely the claim that the ontology and epistemology underlying AI development is rationalist and individualist and as such is marked by blind spots for the social and in particular situated or situational embedding of AI (Suchman, 1987, 2007; Star, 1989). Secondly they delve into the issue of whether and how social studies of technology can account for AI testing in real-world settings in situational terms. And thirdly they ask the question of what does this tell us about possible tensions and alignments between different “definitions of the situation” assumed in social studies engineering and computer science in relation to AI. Finally they discuss the ramifications for their methodological commitment to “the situation” in the social study of AI.
Noortje Marres is Professor of Science Technolpgy and Society at the Centre for Interdisciplinary Methodology at the University of Warwick and Guest Professor at Media of Cooperation Collaborative Research Centre at the University of Siegen. She published two monographs Material Participation (2012) and Digital Sociology (2017).
Philippe Sormani is Senior Researcher and Co-Director of the Science and Technology Studies Lab at the University of Lausanne. Drawing on and developing ethnomethodology he has published on experimentation in and across different fields of activity ranging from experimental physics (in Re- specifying Lab Ethnography, 2014) to artistic experiments (in Practicing Art/Science, 2019).
The paper »Testing ‘AI’: Do We Have a Situation?« is published as part of the Working Paper Series of the CRC 1187 which promotes inter- and transdisciplinary media research and provides an avenue for rapid publication and dissemination of ongoing research located at or associated with the CRC. The purpose of the series is to circulate in-progress research to the wider research community beyond the CRC. All Working Papers are accessible via the website.
Image caption: Ghost #8 (Memories of a mise en abîme with a bare back in front of an untamable tentacular screen), experimenting with OpenAI Dall-E, Maria Guta and Lauren Huret (Iris), 2022. (Courtesy of the artists)

As part of the forestscapes project we’re organising a listening lab at re:publica 23, the digital society festival in Berlin, 5-7th June 2023:
How can generative soundscape composition enable different perspectives on forests in an era of planetary crisis? The forestscapes listening lab explores how sound can serve as a medium for collective inquiry into forests as living cultural landscapes.
The soundscapes are composed with folders of sound from different sources, including field recordings from researchers, sound artists and forest practitioners, as well as online sounds from the web, social media and sound archives. They are composed using custom scripts with the open source supercollider software as well as open source norns device, a “sound machine for the exploration of time and space”.
The re:publica installation will include soundscapes from workshops in London and Berlin – including some new pieces from the Environmental Data, Media, and the Humanities hackathon last week.
Cross-posted from jonathangray.org.
Following the recent release of Gephi Lite, an open-source web-based visual network exploration tool, we interviewed its developers about the background of the project, what they’ve done and future plans…

What is Gephi Lite?
Gephi Lite can actually be defined in two ways. The first definition follows the name we chose: Gephi Lite is a lighter version of the Gephi desktop software, targeting users who need to work on smaller networks with less complex operations in mind.
The second definition is more focused on the technical context: Gephi Lite is a serverless web application to drive visual network analysis. There are no more requirements than an internet connection and a modern web browser.
Continue reading
Social Studies of Science has just published “Seven moments with Bruno Latour” by Noortje Marres, Professor in Science, Technology and Society at the Centre for Interdisciplinary Methodologies (University of Warwick) and founding member of the Public Data Lab.
The piece moves across memories, conversations and encounters from 1999 to 2022, situating explorations of issue mapping, controversy mapping, hyperlink analysis, ecological politics, feminist science and technology studies, modes of existence, protocols for collective inquiry, and arts-based methods.
An excerpt on “Limburg, 1999”:
It is a rainy afternoon in Limburg, in the south of the Netherlands. I have taken a local train from Maastricht to Kerkrade to visit Rolduc, a Catholic abbey that also hosts academic conferences, and where the Dutch Graduate School for Science, Technology and Modern Culture (WTMC) is holding a meeting. I have a poster with me, a map of the Genetically Modified Food debate on the Web, a circle of nodes representing the websites of organizations that take positions on the issue of GM Foods, and the hyperlinks that connect them. I made this poster with colleagues at the Jan van Eyck Academy, a post-graduate art school in Maastricht, where am working as a theorist-in-residence in the Design Department, as part of a team led by Richard Rogers, the media scholar, to develop digital methods of issue mapping.
It is wet and windy when I arrive in Kerkrade, and I approach the old, tall buildings of Rolduc abbey with what I can only call trepidation. Bruno has invited me to show our poster at the WTMC conference, but I am not at all sure that this was a good idea. I am not even a PhD student, and am based in an art school. I am a stranger. Fortunately, by the time I walk into the conference the poster session is about to start, and I am relieved that I can put my poster on the wall and simply stand there, next to my poster, in a clearly defined role. Bruno asks a lot of questions. Who are these organizations? What can the hyperlinks between them tell us about their ‘position’ in the controversy, and about the controversy itself? He does not ask: Why are you showing us a … data visualization? He does not ask: What are you doing, art or social science? He does not ask: If your poster presents a study of public controversy, then why are you doing this work in a graphic design department? Others join us and we have a conversation.
In 1999, to create what we would later call digital controversy maps was to step into an under-defined, interdisciplinary space. Our work at the Jan van Eyck Akademie brought together STS with design research, computing, internet studies and environmental politics, and at the time this did not make much institutional sense. Our work also looks strange. Indeed, how can one show a network visualisation and call it a debate? As it turned out Bruno Latour was strongly supportive of our approach: the development of interdisciplinary methods of inquiry, which combine social science with art and design, became one of his principal occupations in the decades that followed.
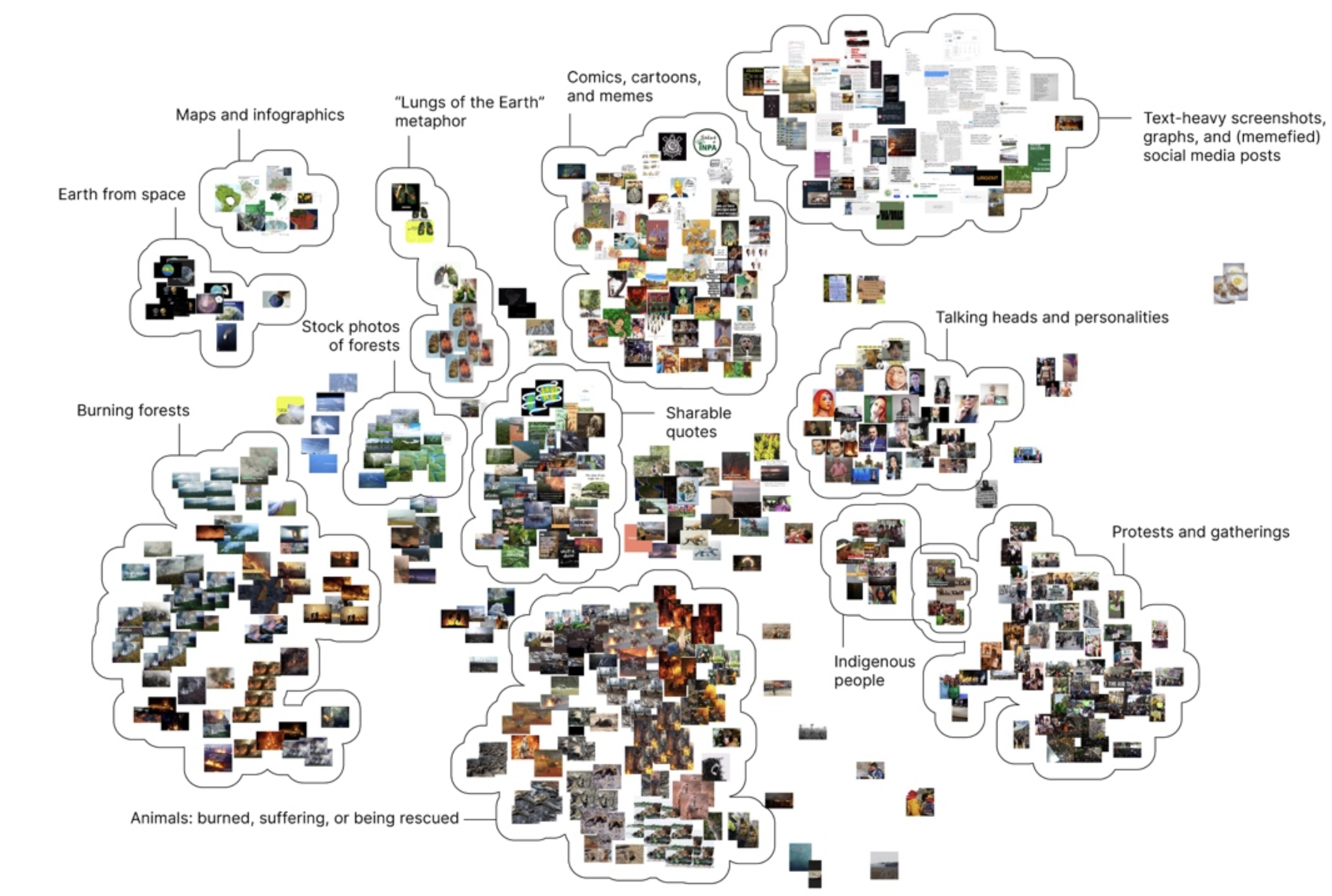
A new article on “Visual Models for Social Media Image Analysis: Groupings, Engagement, Trends, and Rankings” co-authored by Public Data Lab researchers Gabriele Colombo, Liliana Bounegru and Jonathan Gray has just been published in the International Journal of Communication (IJOC). It is available as an open access PDF. Here’s the abstract:
With social media image analysis, one collects and interprets online images for the study of topical affairs. This analytical undertaking requires formats for displaying collections of images that enable their inspection. First, we discuss features of social media images to make a case for studying them in groups (rather than individually): multiplicity, circulation, modification, networkedness, and platform specificity. In all, these offer reasons and means for an approach to social media image research that privileges the collection of images as its analytical object. Second, taking the 2019 Amazon rainforest fires as a case study, we present four visual models for analyzing collections of social media images. Each visual model matches a distinctive spatial arrangement with a type of analysis: grouping images by theme with clusters, surfacing dominant images and their engagement with treemaps, following image trends with plots, and comparing image rankings across platforms with grids.

Soundscapes as method
How can soundscapes be used as a way to attend to forest life and the many different ways that we narrate and relate to forests, forest issues and forest protection and restoration efforts?
Forests and their wider ecologies are presented not only as sites of conservation and relaxation, but also as crucial infrastructures in addressing and building resilience against the effects of climate change; habitats for endangered species; hotspots of biodiversity; part of poverty alleviation programmes; sites for ecotourism, health and wellbeing; scenes of neocolonial afforestation; backdrops for corporate greenwashing; landscapes of danger, violence, destruction and resource conflicts; and places where different kinds of planetary futures may emerge. Forests are involved in collective life in many ways.
In this context, the forestscapes project will explore, document and demonstrate generative arts-based methods for recomposing collections of sound materials to support “collective inquiry” into forests as living cultural landscapes. It aims to facilitate interdisciplinary exchanges between natural scientists, social scientists, arts and humanities researchers, artists and public-spirited organisations and institutions working on forest issues.
While many previous works have explored sound as a medium for sensory immersion, (e.g. field recordings), forestscapes explores how recomposing sound material may explore forests as mediatised and contested cultural landscapes: diverse sites of many different (and marginalised) kinds of beings, relations, histories and representations. As part of the project we will co-create new sound works, as well as generative composition techniques using open source software and hardware.
Research on visual methods has explored how to work with “folders of images”, including formats for the re-arrangement of images for collective interpretation. Forestscapes will explore generative methods and techniques for working with “folders of sound” – whether folders of site-based recordings or collections of sounds associated with a particular place gathered from the web and social media.
Further details and materials from the project will be added here.
Call for folders of forest sounds
As part of the project we have an open call for folders of forest sounds. If you have a collection of forest sounds related to a particular site and you’d be interested in exploring soundscaping techniques, we’d love to hear from you.
What? We welcome sounds collected in different contexts, i.e. research projects involving forests in some ways (e.g. ecological restoration, study of climate change impacts, fieldwork, etc); sounds recorded during walks and trips; as well as material collected online.
How? You can tell us about your folders of forest sounds here.
Who? We’re keen to hear from everyone with collections of forest sounds – whether you’re a forest scientist with bioacoustic recordings; an environmental organisation exploring sound as a medium of community engagement; a new media researcher gathering online materials; an ethnographer working with sound materials; a musician working with field recordings from a particular forest site; an artist interested in generative compositional techniques with ecological sounds; or a walker who has gathered a collection of sounds from a forest you often go to.
When? Please submit your files by 17th March 2023.
The forestscapes project is a collaboration between the Department of Geography, the Department of Digital Humanities, the Centre for Digital Culture, the Centre for Attention Studies, the Digital Futures Institute and the Environmental Humanities Network at King’s College London, together with the Public Data Lab. It is supported by the National Environmental Research Council.
A new article on “Staying with the trouble of networks” co-authored by Daniela van Geenen, Jonathan Gray, Liliana Bounegru, Tommaso Venturini, Mathieu Jacomy and Axel Meunier has just been published in Frontiers in Big Data. It is available open access in html and PDF versions. Here’s the abstract:
Networks have risen to prominence as intellectual technologies and graphical representations, not only in science, but also in journalism, activism, policy, and online visual cultures. Inspired by approaches taking trouble as occasion to (re)consider and reflect on otherwise implicit knowledge practices, in this article we explore how problems with network practices can be taken as invitations to attend to the diverse settings and situations in which network graphs and maps are created and used in society. In doing so, we draw on cases from our research, engagement and teaching activities involving making networks, making sense of networks, making networks public, and making network tools. As a contribution to “critical data practice,” we conclude with some approaches for slowing down and caring for network practices and their associated troubles to elicit a richer picture of what is involved in making networks work as well as reconsidering their role in collective forms of inquiry.
The TANTLab is hosting a virtual panel on Jan 25 (5.30 CET) where Public Data Lab members Tommaso Venturini and David Moats will participate together with Laura Nelson from University of British Columbia. The theme of the panel is whether the influx of computational methods challenges ingrained epistemic binaries in SSH. We define an epistemic binary as a dichotomy that (perhaps artificially) separates knowledge production into different kinds.
The panel is arranged as part of the process of editing the forthcoming ‘handbook of digital and computational SSH’ (edited by Public Data Lab members Anders Koed Madsen & Anders Kristian Munk on Edward Elgar). Each of the three authors discuss such binaries in their chapters and this panel brings them together to reflect more broardly on the fate of binaries in contemporary digital knowledge production.
You can read more here and join here.
The following is a cross-post from Rina Tsubaki at the European Forest Institute, drawing on digital methods recipes and approaches developed with the Public Data Lab as part a broader collaboration around the SUPERB project on upscaling forest restoration.
Elon Musk’s takeover of Twitter has prompted confusion among its users and concerns about the platform’s future. Musk’s tweets are gathering daily attention due to large-scale layoffs and safety concerns around the new paid blue verification mark. To make things worse, as its engineers are on their way out of the door, users are also experiencing various technical glitches on the platform. Millions of users – including journalists, researchers and organisations – are already signing up on alternative platforms to be prepared for the platform’s deterioration and demise.
While no one can predict Twitter’s future, it remains widely used by politicians, scientists, companies, NGOs and influencers who are still busy posting on the platform. This includes COP27 in Egypt, where Twitter was one of the main platforms to report on the event. #cop27 has been tweeted over 2.85 million times since 5 November 2022.
Social media platforms can give us additional insights into how broader publics make connections between forest restoration and other social, economic and environmental issues. To see which issues and narratives around forest restoration have been brought up on Twitter in the lead-up to the event, we’ve carried out a series of small explorations based on the digital methods recipes developed by our colleagues at the Department of Digital Humanities, King’s College London and the Public Data Lab who are part of the SUPERB consortium led by EFI. This has been a good way to see if EFI could use these methods independently to understand international events as they unfold.
We usually see a spike in hashtag usage a few days before global events like the COPs. Using #cop27, we collected 217,189 tweets between 5 and 7 November 2022. We then examined the top 1000 hashtags to see which kinds of forest-related issues are present.
Continue reading