How are digital objects – such as hashtags, links, likes and images – involved in ecological politics?
Public Data Lab researchers Liliana Bounegru, Gabriele Colombo and Jonathan Gray explore this in a new chapter on “#amazonfires and the online composition of ecological politics” as part of a book on digital ecologies: mediating more-than-human worlds which has just been published on Manchester University Press.
Here’s the abstract for the chapter:
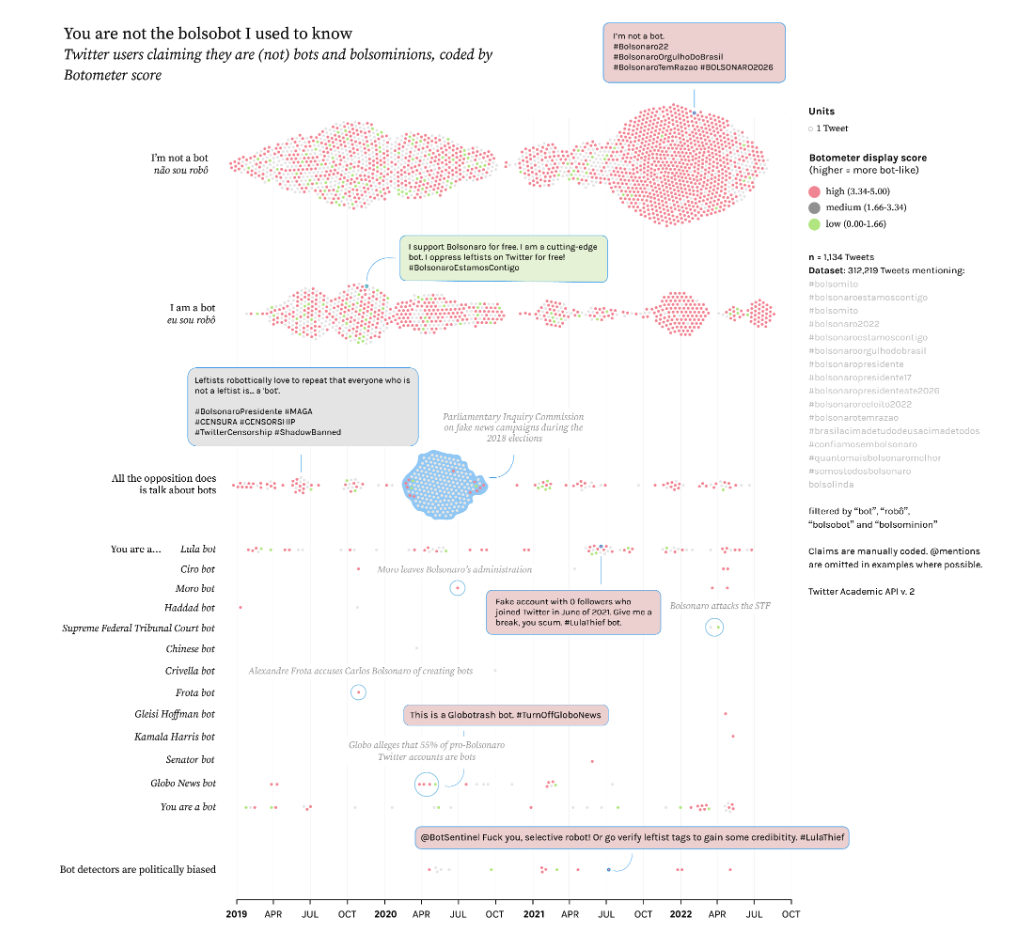
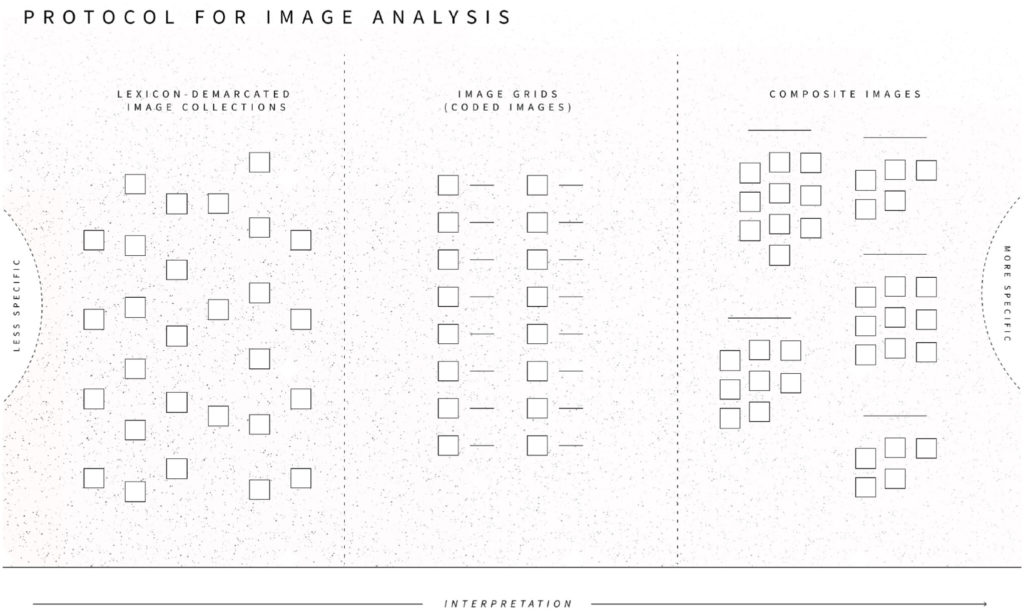
How are digital objects such as hashtags, links, likes and images involved in the production of forest politics? This chapter explores this through collaborative research on the dynamics of online engagement with the 2019 Amazon forest fires. Through a series of empirical vignettes with visual materials and data from social media, we examine how digital platforms, objects and devices perform and organise relations between forests and a wide variety of societal actors, issues, cultures – from bots to boycotts, agriculture to eco-activism, scientists to pop stars, indigenous communities to geopolitical interventions. Looking beyond concerns with the representational (in-)fidelities of forest media, we consider the role of collaborative methodological experiments with co-hashtag networks, cross-platform analysis, composite images and image-text variations in tracing, eliciting and unfolding the digital mediation of ecological politics. Thinking along with research on the social lives of methods, we consider the role of digital data, methods and infrastructures in the composition and recomposition of problems, relations and ontologies of forests in society.
Here’s the book blurb:
Digital ecologies draws together leading social science and humanities scholars to examine how digital media are reshaping the futures of conservation, environmentalism, and ecological politics. The book offers an overview of the emerging field of interdisciplinary digital ecologies research by mapping key debates and issues in the field, with original empirical chapters exploring how livestreams, sensors, mobile technologies, social media platforms, and software are reconfiguring life in profound ways. The collection traverses contexts ranging from animal exercise apps, to surveillance systems on the high seas, and is organised around the themes of encounters, governance, and assemblages. Digital ecologies also includes an agenda-setting intervention by the book’s editors, and three closing chapter-length provocations by leading scholars in digital geographies, the environmental humanities, and media theory that set out trajectories for future research.